
еә”з”ЁиғҢжҷҜ
еӨ§ж•°жҚ®пјҢITиЎҢдёҡзҡ„еҸҲдёҖж¬ЎжҠҖжңҜеҸҳйқ©пјҢеӨ§ж•°жҚ®зҡ„жөӘжҪ®жұ№ж¶ҢиҖҢиҮіпјҢеҜ№еӣҪ家治зҗҶгҖҒдјҒдёҡеҶізӯ–е’ҢдёӘдәәз”ҹжҙ»йғҪеңЁдә§з”ҹж·ұиҝңзҡ„еҪұе“ҚпјҢ并е°ҶжҲҗдёәеӨ§ж•°жҚ®гҖҒзү©иҒ”зҪ‘д№ӢеҗҺдҝЎжҒҜжҠҖжңҜдә§дёҡйўҶеҹҹеҸҲдёҖйҮҚеӨ§еҲӣж–°еҸҳйқ©гҖӮжңӘжқҘзҡ„еҚҒе№ҙе°ҶжҳҜдёҖдёӘвҖңеӨ§ж•°жҚ®вҖқеј•йўҶзҡ„жҷә慧科жҠҖзҡ„ж—¶д»ЈгҖҒйҡҸзқҖзӨҫдәӨзҪ‘з»ңзҡ„йҖҗжёҗжҲҗзҶҹпјҢ移еҠЁеёҰе®Ҫиҝ…йҖҹжҸҗеҚҮгҖҒеӨ§ж•°жҚ®гҖҒзү©иҒ”зҪ‘еә”з”ЁжӣҙеҠ дё°еҜҢгҖҒжӣҙеӨҡзҡ„дј ж„ҹи®ҫеӨҮгҖҒ移еҠЁз»Ҳз«ҜжҺҘе…ҘеҲ°зҪ‘з»ңпјҢз”ұжӯӨиҖҢдә§з”ҹзҡ„ж•°жҚ®еҸҠеўһй•ҝйҖҹеәҰе°ҶжҜ”еҺҶеҸІдёҠзҡ„д»»дҪ•ж—¶жңҹйғҪиҰҒеӨҡгҖҒйғҪиҰҒеҝ«гҖӮ

ж•°жҚ®жҠҖжңҜеҸ‘еұ•еҺҶеҸІ
и®ӨиҜҶеӨ§ж•°жҚ®
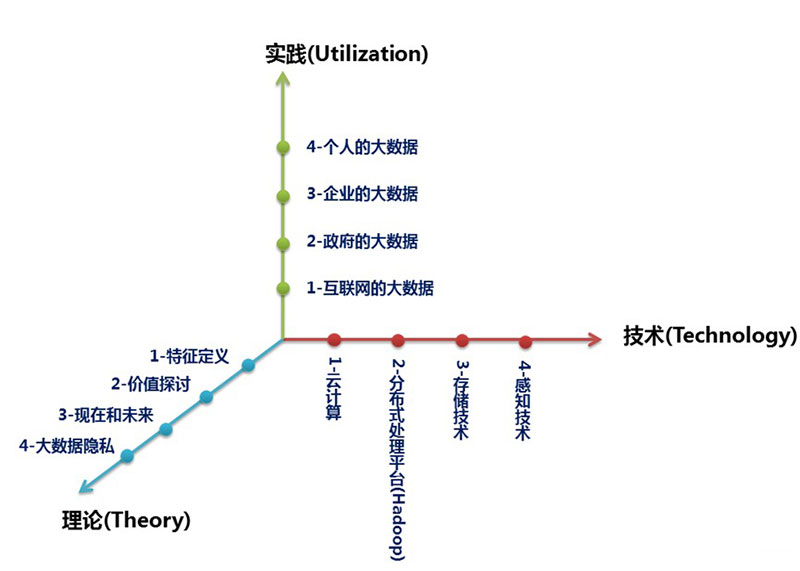
第дёҖеұӮйқўжҳҜзҗҶи®әпјҢзҗҶи®әжҳҜи®ӨзҹҘзҡ„еҝ…з»ҸйҖ”еҫ„пјҢд№ҹжҳҜиў«е№ҝжіӣи®ӨеҗҢе’Ңдј ж’ӯзҡ„еҹәзәҝгҖӮжҲ‘дјҡд»ҺеӨ§ж•°жҚ®зҡ„зү№еҫҒе®ҡд№үзҗҶи§ЈиЎҢдёҡеҜ№еӨ§ж•°жҚ®зҡ„ж•ҙдҪ“жҸҸз»ҳе’Ңе®ҡжҖ§пјӣд»ҺеҜ№еӨ§ж•°жҚ®д»·еҖјзҡ„жҺўи®ЁжқҘж·ұе…Ҙи§ЈжһҗеӨ§ж•°жҚ®зҡ„зҸҚиҙөжүҖеңЁпјӣд»ҺеҜ№еӨ§ж•°жҚ®зҡ„зҺ°еңЁе’ҢжңӘжқҘеҺ»жҙһжӮүеӨ§ж•°жҚ®зҡ„еҸ‘еұ•и¶ӢеҠҝпјӣд»ҺеӨ§ж•°жҚ®йҡҗз§ҒиҝҷдёӘзү№еҲ«иҖҢйҮҚиҰҒзҡ„и§Ҷи§’е®Ўи§Ҷдәәе’Ңж•°жҚ®д№Ӣй—ҙзҡ„й•ҝд№…еҚҡејҲгҖӮ
第дәҢеұӮйқўжҳҜжҠҖжңҜпјҢжҠҖжңҜжҳҜеӨ§ж•°жҚ®д»·еҖјдҪ“зҺ°зҡ„жүӢж®өе’ҢеүҚиҝӣзҡ„еҹәзҹігҖӮжҲ‘е°ҶеҲҶеҲ«д»Һдә‘и®Ўз®—гҖҒеҲҶеёғејҸеӨ„зҗҶжҠҖжңҜгҖҒеӯҳеӮЁжҠҖжңҜе’Ңж„ҹзҹҘжҠҖжңҜзҡ„еҸ‘еұ•жқҘиҜҙжҳҺеӨ§ж•°жҚ®д»ҺйҮҮйӣҶгҖҒеӨ„зҗҶгҖҒеӯҳеӮЁеҲ°еҪўжҲҗз»“жһңзҡ„ж•ҙдёӘиҝҮзЁӢгҖӮ
第дёүеұӮйқўжҳҜе®һи·өпјҢе®һи·өжҳҜеӨ§ж•°жҚ®зҡ„жңҖз»Ҳд»·еҖјдҪ“зҺ°гҖӮжҲ‘е°ҶеҲҶеҲ«д»Һдә’иҒ”зҪ‘зҡ„еӨ§ж•°жҚ®пјҢж”ҝеәңзҡ„еӨ§ж•°жҚ®пјҢдјҒдёҡзҡ„еӨ§ж•°жҚ®е’ҢдёӘдәәзҡ„еӨ§ж•°жҚ®еӣӣдёӘж–№йқўжқҘжҸҸз»ҳеӨ§ж•°жҚ®е·Із»Ҹеұ•зҺ°зҡ„зҫҺеҘҪжҷҜиұЎеҸҠеҚіе°Ҷе®һзҺ°зҡ„и“қеӣҫгҖӮ
еӨ§ж•°жҚ®е®ҡд№үдёҺзү№зӮ№
вҖңеӨ§ж•°жҚ®вҖқжҳҜдёҖдёӘж¶өзӣ–еӨҡз§ҚжҠҖжңҜзҡ„жҰӮеҝөпјҢз®ҖеҚ•ең°иҜҙпјҢжҳҜжҢҮж— жі•еңЁдёҖе®ҡж—¶й—ҙеҶ…用常规иҪҜ件е·Ҙе…·еҜ№е…¶еҶ…е®№иҝӣиЎҢжҠ“еҸ–гҖҒз®ЎзҗҶе’ҢеӨ„зҗҶзҡ„ж•°жҚ®йӣҶеҗҲгҖӮIBMе°ҶвҖңеӨ§ж•°жҚ®вҖқзҗҶеҝөе®ҡд№үдёә4дёӘVпјҢеҚіеӨ§йҮҸеҢ–(Volume)гҖҒеӨҡж ·еҢ–(Variety)гҖҒеҝ«йҖҹеҢ–(Velocity)еҸҠз”ұжӯӨдә§з”ҹзҡ„д»·еҖј(Value)гҖӮ

иҰҒзҗҶи§ЈеӨ§ж•°жҚ®иҝҷдёҖжҰӮеҝөпјҢйҰ–е…ҲиҰҒд»Һ"еӨ§"е…ҘжүӢпјҢ"еӨ§"жҳҜжҢҮж•°жҚ®и§„жЁЎпјҢеӨ§ж•°жҚ®дёҖиҲ¬жҢҮеңЁ10TB(1TB=1024GB)规模д»ҘдёҠзҡ„ж•°жҚ®йҮҸгҖӮеӨ§ж•°жҚ®еҗҢиҝҮеҺ»зҡ„жө·йҮҸж•°жҚ®жңүжүҖеҢәеҲ«пјҢе…¶еҹәжң¬зү№еҫҒеҸҜд»Ҙз”Ё4дёӘVжқҘжҖ»з»“(Vol-umeгҖҒVarietyгҖҒValueе’ҢVeloc-ity)пјҢеҚідҪ“йҮҸеӨ§гҖҒеӨҡж ·жҖ§гҖҒд»·еҖјеҜҶеәҰдҪҺгҖҒйҖҹеәҰеҝ«гҖӮ

ж•°жҚ®дҪ“йҮҸе·ЁеӨ§гҖӮд»ҺTBзә§еҲ«пјҢи·ғеҚҮеҲ°PBзә§еҲ«гҖӮ
ж•°жҚ®зұ»еһӢз№ҒеӨҡпјҢеҰӮеүҚж–ҮжҸҗеҲ°зҡ„зҪ‘з»ңж—Ҙеҝ—гҖҒи§Ҷйў‘гҖҒеӣҫзүҮгҖҒең°зҗҶдҪҚзҪ®дҝЎжҒҜпјҢзӯүзӯүгҖӮ
д»·еҖјеҜҶеәҰдҪҺгҖӮд»Ҙи§Ҷйў‘дёәдҫӢпјҢиҝһз»ӯдёҚй—ҙж–ӯзӣ‘жҺ§иҝҮзЁӢдёӯпјҢеҸҜиғҪжңүз”Ёзҡ„ж•°жҚ®д»…д»…жңүдёҖдёӨз§’гҖӮ
еӨ„зҗҶйҖҹеәҰеҝ«гҖӮ1з§’е®ҡеҫӢгҖӮжңҖеҗҺиҝҷдёҖзӮ№д№ҹжҳҜе’Ңдј з»ҹзҡ„ж•°жҚ®жҢ–жҺҳжҠҖжңҜжңүзқҖжң¬иҙЁзҡ„дёҚеҗҢгҖӮзү©иҒ”зҪ‘гҖҒдә‘и®Ўз®—гҖҒ移еҠЁдә’иҒ”зҪ‘гҖҒиҪҰиҒ”зҪ‘гҖҒжүӢжңәгҖҒе№іжқҝз”өи„‘гҖҒPCд»ҘеҸҠйҒҚеёғең°зҗғеҗ„дёӘи§’иҗҪзҡ„еҗ„з§Қеҗ„ж ·зҡ„дј ж„ҹеҷЁпјҢж— дёҖдёҚжҳҜж•°жҚ®жқҘжәҗжҲ–иҖ…жүҝиҪҪзҡ„ж–№ејҸгҖӮ
еӨ§ж•°жҚ®жҠҖжңҜжҳҜжҢҮд»Һеҗ„з§Қеҗ„ж ·зұ»еһӢзҡ„е·ЁйҮҸж•°жҚ®дёӯпјҢеҝ«йҖҹиҺ·еҫ—жңүд»·еҖјдҝЎжҒҜзҡ„жҠҖжңҜгҖӮи§ЈеҶіеӨ§ж•°жҚ®й—®йўҳзҡ„ж ёеҝғжҳҜеӨ§ж•°жҚ®жҠҖжңҜгҖӮзӣ®еүҚжүҖиҜҙзҡ„"еӨ§ж•°жҚ®"дёҚд»…жҢҮж•°жҚ®жң¬иә«зҡ„规模пјҢд№ҹеҢ…жӢ¬йҮҮйӣҶж•°жҚ®зҡ„е·Ҙе…·гҖҒе№іеҸ°е’Ңж•°жҚ®еҲҶжһҗзі»з»ҹгҖӮеӨ§ж•°жҚ®з ”еҸ‘зӣ®зҡ„жҳҜеҸ‘еұ•еӨ§ж•°жҚ®жҠҖжңҜ并е°Ҷе…¶еә”з”ЁеҲ°зӣёе…ійўҶеҹҹпјҢйҖҡиҝҮи§ЈеҶіе·ЁйҮҸж•°жҚ®еӨ„зҗҶй—®йўҳдҝғиҝӣе…¶зӘҒз ҙжҖ§еҸ‘еұ•гҖӮеӣ жӯӨпјҢеӨ§ж•°жҚ®ж—¶д»ЈеёҰжқҘзҡ„жҢ‘жҲҳдёҚд»…дҪ“зҺ°еңЁеҰӮдҪ•еӨ„зҗҶе·ЁйҮҸж•°жҚ®д»ҺдёӯиҺ·еҸ–жңүд»·еҖјзҡ„дҝЎжҒҜпјҢд№ҹдҪ“зҺ°еңЁеҰӮдҪ•еҠ ејәеӨ§ж•°жҚ®жҠҖжңҜз ”еҸ‘пјҢжҠўеҚ ж—¶д»ЈеҸ‘еұ•зҡ„еүҚжІҝгҖӮ
ж•°жҚ®йҮҸеӨ§гҖҒж•°жҚ®з§Қзұ»еӨҡгҖҒ иҰҒжұӮе®һж—¶жҖ§ејәгҖҒж•°жҚ®жүҖи•ҙи—Ҹзҡ„д»·еҖјеӨ§гҖӮеңЁеҗ„иЎҢеҗ„дёҡеқҮеӯҳеңЁеӨ§ж•°жҚ®пјҢдҪҶжҳҜдј—еӨҡзҡ„дҝЎжҒҜе’Ңе’ЁиҜўжҳҜзә·з№ҒеӨҚжқӮзҡ„пјҢжҲ‘们йңҖиҰҒжҗңзҙўгҖҒеӨ„зҗҶгҖҒеҲҶжһҗгҖҒеҪ’зәігҖҒжҖ»з»“е…¶ж·ұеұӮж¬Ўзҡ„规еҫӢгҖӮ
еӨ§ж•°жҚ®зҡ„йҮҮйӣҶ
科еӯҰжҠҖжңҜеҸҠдә’иҒ”зҪ‘зҡ„еҸ‘еұ•пјҢжҺЁеҠЁзқҖеӨ§ж•°жҚ®ж—¶д»Јзҡ„жқҘдёҙпјҢеҗ„иЎҢеҗ„дёҡжҜҸеӨ©йғҪеңЁдә§з”ҹж•°йҮҸе·ЁеӨ§зҡ„ж•°жҚ®зўҺзүҮпјҢж•°жҚ®и®ЎйҮҸеҚ•дҪҚе·Ід»Һд»ҺByteгҖҒKBгҖҒMBгҖҒGBгҖҒTBеҸ‘еұ•еҲ°PBгҖҒEBгҖҒZBгҖҒYBз”ҡиҮіBBгҖҒNBгҖҒDBжқҘиЎЎйҮҸгҖӮеӨ§йҮҸзҡ„еҰӮж•°еҰӮжһңдёҚеҠ д»ҘеҲҶжһҗе’ҢеҲ©з”ЁпјҢе°ұжҳҜдёҖе Ҷж— з”Ёзҡ„ж•°еӯ—пјҢиҖҢеңЁзҺ°д»Ҡ科жҠҖзҡ„иғҢжҷҜдёӢпјҢеӨ§ж•°жҚ®зҡ„ж ·жң¬йҮҮйӣҶе·Із»ҸдёҚеҶҚжҳҜжҠҖжңҜй—®йўҳпјҢеҸӘжҳҜйқўеҜ№еҰӮжӯӨдј—еӨҡзҡ„ж•°жҚ®пјҢжҲ‘们жҖҺж ·жүҚиғҪжүҫеҲ°е…¶еҶ…еңЁи§„еҫӢпјҢжүҚжҳҜеҪ“дёӢжңҖиҝ«еҲҮзҡ„йңҖжұӮгҖӮеҰӮдҪ•д»Һз№ҒжқӮзҡ„ж•°жҚ®дёӯйҮҮйӣҶеҮәжңүж•ҲдҝЎжҒҜпјҢжҳҜеҰӮд»ҠеӨ§ж•°жҚ®йҮҮйӣҶзҡ„йҮҚдёӯд№ӢйҮҚ
еӨ§ж•°жҚ®зҡ„жҢ–жҺҳе’ҢеӨ„зҗҶ
з”ұдәҺеӨ§ж•°жҚ®еәһеӨ§зҡ„ж•°жҚ®йҮҸпјҢдәәе·Ҙзҡ„иҝҗз®—жҳҜеҝ…з„¶ж— жі•иҫҫеҲ°йңҖжұӮзҡ„гҖӮдҪҶжҳҜе…ҲдёӢ科жҠҖзҡ„еҸ‘еұ•и®©ж•°жҚ®е·Із»Ҹд»ҺиҝҮеҺ»зҡ„GBпјҢTBеҸ‘еұ•еҲ°еҰӮд»ҠTBеҲ°PBзҡ„зә§еҲ«пјҢжҷ®йҖҡи®Ўз®—жңәзҡ„иғҪеҠӣе·Із»Ҹж— жі•ж»Ўи¶іеҸ‘ж•°жҚ®и®Ўз®—зҡ„йңҖжұӮгҖӮжүҖд»Ҙеҗ„з§ҚеӨ§еһӢи®Ўз®—жңәи¶…зә§и®Ўз®—жңәеә”иҝҗиҖҢз”ҹгҖӮ然иҖҢ硬件满足дәҶйңҖжұӮпјҢдҪҶжҳҜиҪҜ件пјҢжһ¶жһ„пјҢе’Ңеә”з”Ёж–№ејҸеҚҙж— жі•иҫҫеҲ°еҫҲеҘҪзҡ„ж•ҲжһңгҖӮеҰӮзҺ°еңЁдё–з•ҢдёҠжңүеҫҲеӨҡе·ЁеһӢи®Ўз®—жңәпјҢи¶…зә§и®Ўз®—жңәгҖӮдҪҶе…ұеҗҢйқўдёҙзҡ„й—®йўҳжҳҜеҰӮдҪ•жңүж•Ҳзҡ„еҲ©з”Ёе®ғзҡ„иө„жәҗгҖӮ
иҰҒжҸҗй«ҳж•°жҚ®еӨ„зҗҶжҖ§иғҪпјҢе°ұдёҖе®ҡиҰҒз”ЁеҲ°е№¶иЎҢи®Ўз®—пјҢеҲҶеёғејҸиҝҗз®—зҡ„жҠҖжңҜпјҢиҖҢеңЁзҪ‘з»ңпјҢе·ЁеһӢжңәйЈһйҖҹеҸ‘еұ•зҡ„д»ҠеӨ©пјҢдҫқжүҳеҲҶеёғејҸе’ҢиҷҡжӢҹеҢ–жҠҖжңҜзҡ„дә‘и®Ўз®—д№ҹеҝ…然жҲҗдёәдәҶзғӯй—Ёзҡ„жҠҖжңҜйҖүжӢ©гҖӮеҸҜд»ҘиҜҙи§ЈеҶіеҘҪеӨ§ж•°жҚ®зҡ„й—®йўҳпјҢ并иЎҢи®Ўз®—пјҢеҲҶеёғејҸжҠҖжңҜпјҢдә‘и®Ўз®—зӯүжҳҜеҝ…йЎ»иҰҒдәҶи§Је’ҢжҺҢжҸЎзҡ„жҠҖиғҪпјҢ并且他们зӣёдә’дҫқиө–пјҢеҸҲеҚҸеҗҢеҗҲдҪңеӨ„иғҪејәеӨ§зҡ„еҠҹиғҪпјҢеҰӮеҲҶеёғејҸж•°жҚ®еә“пјҢдә‘еӯҳеӮЁзӯүеңЁеӨ§ж•°жҚ®зҡ„жҢ–жҺҳе’ҢеӨ„зҗҶж–№йқўйғҪиө·еҲ°дәҶиҮіе…ійҮҚиҰҒзҡ„дҪңз”ЁгҖӮ
еӨ§ж•°жҚ®жҠҖжңҜзҡ„дё»иҰҒеә”з”ЁйўҶеҹҹ
1. еҲҶеёғејҸеӯҳеӮЁи®Ўз®—жһ¶жһ„пјҲејәзғҲжҺЁиҚҗпјҡHadoopпјү
2. еҲҶеёғејҸзЁӢеәҸи®ҫи®ЎпјҲеҢ…еҗ«пјҡApache PigжҲ–иҖ…Hiveпјү
3. еҲҶеёғејҸж–Ү件系з»ҹпјҲжҜ”еҰӮпјҡGoogle GFSпјү
4. еӨҡз§ҚеӯҳеӮЁжЁЎеһӢпјҢдё»иҰҒеҢ…еҗ«ж–ҮжЎЈпјҢеӣҫпјҢй”®еҖјпјҢж—¶й—ҙеәҸеҲ—иҝҷеҮ з§ҚеӯҳеӮЁжЁЎеһӢпјҲжҜ”еҰӮпјҡBigTableпјҢApolloпјҢ DynamoDBзӯүпјү
5. ж•°жҚ®ж”¶йӣҶжһ¶жһ„пјҲжҜ”еҰӮпјҡKinesisпјҢKaflaпјү
6. йӣҶжҲҗејҖеҸ‘зҺҜеўғпјҲжҜ”еҰӮпјҡR-Studioпјү
7. зЁӢеәҸејҖеҸ‘иҫ…еҠ©е·Ҙе…·пјҲжҜ”еҰӮпјҡеӨ§йҮҸзҡ„第дёүж–№ејҖеҸ‘иҫ…еҠ©е·Ҙе…·пјү
8. и°ғеәҰеҚҸи°ғжһ¶жһ„е·Ҙе…·пјҲжҜ”еҰӮпјҡApache Auroraпјү
9. жңәеҷЁеӯҰд№ пјҲеёёз”Ёзҡ„жңүApache Mahout жҲ– H2Oпјү
10. жүҳз®Ўз®ЎзҗҶпјҲжҜ”еҰӮпјҡApache Hadoop Benchmarkingпјү
11. е®үе…Ёз®ЎзҗҶпјҲеёёз”Ёзҡ„жңүGatewayпјү
12. еӨ§ж•°жҚ®зі»з»ҹйғЁзҪІпјҲеҸҜд»ҘзңӢдёӢApache Ambariпјү
13. жҗңзҙўеј•ж“Һжһ¶жһ„пјҲ еӯҰд№ жҲ–иҖ…дјҒдёҡйғҪе»әи®®дҪҝз”ЁLuceneжҗңзҙўеј•ж“Һпјү
14. еӨҡз§Қж•°жҚ®еә“зҡ„жј”еҸҳпјҲMySQL/Memcachedпјү
15. е•ҶдёҡжҷәиғҪпјҲеӨ§еҠӣжҺЁиҚҗпјҡJaspersoft пјү
16. ж•°жҚ®еҸҜи§ҶеҢ–пјҲиҝҷдёӘе·Ҙе…·е°ұеҫҲеӨҡдәҶпјҢеҸҜд»Ҙж №жҚ®е®һйҷ…йңҖиҰҒжқҘйҖүжӢ©пјү
17. еӨ§ж•°жҚ®еӨ„зҗҶз®—жі•пјҲ10еӨ§з»Ҹе…ёз®—жі•пјү
еӨ§ж•°жҚ®дёӯеёёз”Ёзҡ„еҲҶжһҗжҠҖжңҜ
u A/BжөӢиҜ•гҖҒе…іиҒ”规еҲҷжҢ–жҺҳгҖҒж•°жҚ®иҒҡзұ»гҖҒ
u ж•°жҚ®иһҚеҗҲе’ҢйӣҶжҲҗгҖҒйҒ—дј з®—жі•гҖҒиҮӘ然иҜӯиЁҖеӨ„зҗҶгҖҒ
u зҘһз»ҸзҪ‘з»ңгҖҒзҘһз»ҸеҲҶжһҗгҖҒдјҳеҢ–гҖҒжЁЎејҸиҜҶеҲ«гҖҒ
u йў„жөӢжЁЎеһӢгҖҒеӣһеҪ’гҖҒжғ…з»ӘеҲҶжһҗгҖҒдҝЎеҸ·еӨ„зҗҶгҖҒ
u з©әй—ҙеҲҶжһҗгҖҒз»ҹи®ЎгҖҒжЁЎжӢҹгҖҒж—¶й—ҙеәҸеҲ—еҲҶжһҗ
еӨ§ж•°жҚ®зҡ„еә”з”Ё
еӨ§ж•°жҚ®еҸҜеә”з”ЁдәҺеҗ„иЎҢеҗ„дёҡпјҢе°Ҷдәә们收йӣҶеҲ°зҡ„еәһеӨ§ж•°жҚ®иҝӣиЎҢеҲҶжһҗж•ҙзҗҶпјҢе®һзҺ°иө„и®Ҝзҡ„жңүж•ҲеҲ©з”ЁгҖӮдёҫдёӘжң¬дё“дёҡзҡ„дҫӢеӯҗпјҢжҜ”еҰӮеңЁеҘ¶зүӣеҹәеӣ еұӮйқўеҜ»жүҫдёҺдә§еҘ¶йҮҸзӣёе…ізҡ„дё»ж•Ҳеҹәеӣ пјҢжҲ‘们еҸҜд»ҘйҰ–е…ҲеҜ№еҘ¶зүӣе…Ёеҹәеӣ з»„иҝӣиЎҢжү«жҸҸпјҢе°Ҫз®ЎжҲ‘们иҺ·еҫ—дәҶжүҖжңүиЎЁеһӢдҝЎжҒҜе’Ңеҹәеӣ дҝЎжҒҜпјҢдҪҶжҳҜз”ұдәҺж•°жҚ®йҮҸеәһеӨ§пјҢиҝҷе°ұйңҖиҰҒйҮҮз”ЁеӨ§ж•°жҚ®жҠҖжңҜпјҢиҝӣиЎҢеҲҶжһҗжҜ”еҜ№пјҢжҢ–жҺҳдё»ж•Ҳеҹәеӣ гҖӮдҫӢеӯҗиҝҳжңүеҫҲеӨҡгҖӮ
еӨ§ж•°жҚ®иғҪеҒҡд»Җд№ҲпјҹжҲ‘们йӮЈд№ҲеӨҡең°ж–№жҺўи®ЁеӨ§ж•°жҚ®пјҢж— йқһжҖ»з»“дёӢжқҘе°ұеҒҡдёү件дәӢпјҡ
第дёҖпјҢеҜ№дҝЎжҒҜзҡ„зҗҶи§ЈгҖӮдҪ еҸ‘зҡ„жҜҸдёҖеј еӣҫзүҮгҖҒжҜҸдёҖдёӘж–°й—»гҖҒжҜҸдёҖдёӘе№ҝе‘ҠпјҢиҝҷдәӣйғҪжҳҜдҝЎжҒҜпјҢдҪ еҜ№иҝҷдёӘдҝЎжҒҜзҡ„зҗҶи§ЈжҳҜеӨ§ж•°жҚ®йҮҚиҰҒзҡ„йўҶеҹҹгҖӮ
第дәҢпјҢз”ЁжҲ·зҡ„зҗҶи§ЈпјҢжҜҸдёӘдәәзҡ„еҹәжң¬зү№еҫҒпјҢдҪ зҡ„жҪңеңЁзҡ„зү№еҫҒпјҢжҜҸдёӘз”ЁжҲ·дёҠзҪ‘зҡ„д№ жғҜзӯүзӯүпјҢиҝҷдәӣйғҪжҳҜеҜ№з”ЁжҲ·зҡ„зҗҶи§ЈгҖӮ
第дёүпјҢе…ізі»гҖӮе…ізі»жүҚжҳҜжҲ‘们зҡ„ж ёеҝғпјҢдҝЎжҒҜдёҺдҝЎжҒҜд№Ӣй—ҙзҡ„е…ізі»пјҢдёҖжқЎеҫ®еҚҡе’ҢеҸҰеӨ–дёҖжқЎеҫ®еҚҡд№Ӣй—ҙзҡ„е…ізі»пјҢдёҖдёӘе№ҝе‘Ҡе’ҢеҸҰеӨ–дёҖдёӘе№ҝе‘Ҡзҡ„е…ізі»гҖӮдёҖжқЎеҫ®еҚҡе’ҢдёҖдёӘи§Ҷйў‘д№Ӣй—ҙзҡ„е…ізі»пјҢиҝҷдәӣеңЁжҲ‘们иӮүзңјеҺ»зңӢзҡ„ж—¶еҖҷжҳҜзӣёеҜ№з®ҖеҚ•зҡ„гҖӮ
еӨ§ж•°жҚ®иҜҙзҡ„йӮЈд№ҲжӮ¬пјҢе…¶е®һдё»иҰҒжҳҜеҒҡдёү件дәӢпјҡеҜ№з”ЁжҲ·зҡ„зҗҶи§ЈгҖҒеҜ№дҝЎжҒҜзҡ„зҗҶи§ЈгҖҒеҜ№е…ізі»зҡ„зҗҶи§ЈгҖӮеҰӮжһңжҲ‘们еңЁиҝҷдёү件дәӢд№Ӣй—ҙиҝҳиҰҒжҸҗдёҖ件дәӢзҡ„иҜқпјҢдёҖдёӘеҸ«и¶ӢеҠҝгҖӮд»–д№ҹжҳҜе…ізі»зҡ„дёҖз§ҚеҸҳз§ҚпјҢеҸӘжҳҜе…ізі»зЁҚеҫ®иҝңдёҖзӮ№пјҢжғ…ж„ҹд№Ӣй—ҙзҡ„еҲҶжһҗпјҢиҝҳжңүжҲ‘们ж”ҝеәңйғЁй—ЁеҒҡзҡ„иҲҶжғ…зӣ‘жҺ§гҖӮд»–еҸҜд»Ҙзӣ‘жҺ§еӨ§и§„жЁЎзҡ„ж•°жҚ®пјҢеҸҜд»ҘеҲҶжһҗеҮәдәәзҡ„еҠЁеҗ‘гҖӮеңЁзҫҺеӣҪзҡ„еҘҪиҺұеқһпјҢиҝҷдёӨе№ҙд№ҹжҳҜеҹәдәҺFACEBOOKе’ҢTIWTTERзҡ„ж•°жҚ®жқҘйў„жөӢеҚіе°ҶдёҠжҳ зҡ„з”өеҪұзҡ„зҘЁжҲҝгҖӮиҝҷд№ҹжҳҜдёҖдёӘи¶ӢеҠҝзҡ„еҲҶжһҗпјҢеҸӘжҳҜжҲ‘们жҠҠиҝҷдёӘи¶ӢеҠҝжҸҗеүҚжқҘгҖӮж ёеҝғе°ұжҳҜиҝҷдёү件дәӢгҖӮ
еӨ§ж•°жҚ®иҜҫзЁӢдҪ“зі»и®ҫзҪ®
дј з»ҹй«ҳж ЎжүҖејҖи®ҫзҡ„ж•°жҚ®зӣёе…ізҡ„иҜҫзЁӢжІЎжңүдё“й—ЁжӯЈеҜ№еӨ§ж•°жҚ®еҶ…е®№зҡ„пјҢжҲ–иҖ…еҜ№еҗ„дёӘеӯҰ科зҡ„еӯҰз”ҹи®ҫзҪ®зӣёеҗҢзҡ„иҜҫзЁӢеҶ…е®№пјҢеҜјиҮҙеӯҰз”ҹеӯҰд№ иҝҮзЁӢдёӯеҸҜиғҪдјҡиҜқеӨ§йҮҸзҡ„ж—¶й—ҙдёҺзІҫеҠӣеңЁдёҺиҮӘиә«дё“дёҡж— е…ізҡ„еҶ…е®№дёҠгҖӮдҪҶжҳҜжғіиҰҒж”№еҸҳиҝҷдёҖзҺ°зҠ¶еҫҖеҫҖдјҡйқўеҜ№еҫҲеӨҡи·ЁеӯҰ科зҡ„жғ…еҶөпјҢжҜ•з«ҹеӨ§ж•°жҚ®йўҶеҹҹдёҚд»…йңҖиҰҒи®Ўз®—жңәзҡ„зҹҘиҜҶпјҢиҝҳйңҖиҰҒж•°жҚ®еҲҶжһҗзҡ„иғҪеҠӣд»ҘеҸҠеҗ„дёӘеӯҰ科жң¬иә«зҡ„зҹҘиҜҶеҶ…е®№пјҢиҝҷеҜ№иҜҫзЁӢи®ҫзҪ®е’ҢжҜҸдёӘйўҶеҹҹиҜҫзЁӢи®ҫзҪ®ж·ұе…ҘзЁӢеәҰжңүиҫғй«ҳзҡ„жҠҠжҺ§иҰҒжұӮпјҢиҝҷд№ҹе°ұжҳҜдёәд»Җд№ҲзҺ°еңЁеӨ§еӨҡж•°зҡ„й«ҳж Ўе’Ңеҹ№и®ӯжңәжһ„и®ҫзҪ®зҡ„иҜҫзЁӢ并дёҚеҗҲзҗҶпјҢеӯҰз”ҹеӯҰд№ д№ӢеҗҺиө°еҗ‘зӨҫдјҡжҖ»и§үеҫ—иғҪеҠӣдјҡжңүжүҖеҒҸе·®е’ҢдёҚи¶ізҡ„еҺҹеӣ гҖӮ
е»әи®ҫж„Ҹд№ү
е®һйӘҢе®ӨеҜ№еӯҰж Ўзҡ„ж„Ҹд№ү
Гҳ еӨ§ж•°жҚ®е®һи®ӯе®һйӘҢе®Өзҡ„е»әи®ҫеҜ№еӯҰж Ўз§‘з ”гҖҒж•ҷеӯҰзҡ„е®һзҺ°е’Ңе®Ңе–„е…·жңүйҮҚиҰҒж„Ҹд№үпјӣ
Гҳ дҝғиҝӣдә§еӯҰз ”дёҖдҪ“еҢ–гҖҒдҝғиҝӣз§‘з ”жҲҗжһңиҪ¬еҢ–并жңҖз»ҲжҲҗдёәз”ҹдә§еҠӣпјӣ
Гҳ жҸҗй«ҳеӯҰж Ўзҡ„з«һдәүеҠӣе’ҢеӯҰз”ҹзҡ„е®һи·өиғҪеҠӣпјӣ
Гҳ жңүеҲ©дәҺжҸҗеҚҮеӯҰж Ўзҡ„е“ҒзүҢгҖӮ
е®һйӘҢе®ӨеҜ№ж•ҷеёҲзҡ„ж„Ҹд№ү
Гҳ е®һйӘҢе®Өж–№дҫҝж•ҷеёҲеҜ№еӯҰе‘ҳе®һйӘҢиҝҮзЁӢиҝӣиЎҢжҠҠжҺ§пјҢжҸҗеҚҮж•ҷеӯҰиҙЁйҮҸпјӣ
Гҳ е®һйӘҢе®ӨжҸҗдҫӣз®ЎзҗҶжңәпјҢдҪҝиҖҒеёҲдҫҝдәҺеҜ№еӯҰз”ҹе®һйӘҢзҡ„з®ЎзҗҶпјҢдҪҝж•ҷеӯҰж•ҲзҺҮжҸҗй«ҳпјӣ
е®һйӘҢе®ӨеҜ№еӯҰз”ҹзҡ„ж„Ҹд№ү
Гҳ еӨ§ж•°жҚ®е®һи®ӯе®һйӘҢе®ӨжҸҗдҫӣдәҶзңҹе®һзҡ„зҪ‘з»ңзҺҜеўғпјҢеҸҜд»Ҙи®©еӯҰз”ҹдәІиҮӘжҗӯе»әзҪ‘з»ңгҖҒдәІиҮӘеҠЁжүӢи°ғиҜ•гҖҒй…ҚзҪ®зҪ‘з»ңпјҢиҝӣиЎҢеӨ§ж•°жҚ®е®һйӘҢпјҢд»ҺиҖҢи®©еӯҰз”ҹзӣҙи§ӮгҖҒе…Ёж–№дҪҚдәҶи§Јеҗ„з§ҚеӨ§ж•°жҚ®е№іеҸ°зҡ„жҗӯе»әе’Ңеә”з”ЁзҺҜеўғпјҢзңҹжӯЈеҠ ж·ұеҜ№еӨ§ж•°жҚ®зҡ„и®ӨиҜҶпјӣ
Гҳ еҗҢж—¶пјҢд№ҹдҪҝеӯҰз”ҹеңЁжҜ•дёҡж—¶жү©еӨ§дәҶжӢ©дёҡзҡ„иҢғеӣҙгҖӮ